
El otro día empecé la casa por el tejado: en el ejercicio 'Estimación del voto mínimo para ganar el televoto en Eurovisión. Caso España-Israel' eché mano de la distribución de Dirichlet sin tener ni idea sobre ella, así que enmiendo el error por escrito.
K componentes, definidas en el rango de valores reales [0,1]. Por ejemplo para K=3 podríamos tener la siguiente serie de 5 muestras (en R usamos el paquete MCMCpack para modelarla):
alpha es un vector con K valores reales α1,...,αK ≥ 0 que modulan individualmente la distribución estadística que seguirá cada una de las variables o componentes de salida.x1+...+xK = 1, resultando ideales para modelar las probabilidades de un evento categórico con K posibilidades (por ejemplo unos % de voto).alpha es verlo con ejemplos gráficos. Si tomamos el caso didáctico K=3 cada vector de salida lo podemos asociar a un punto (x,y,z) del espacio 3D, que estará situado sobre el triángulo equilátero contenido en el plano x+y+z=1 y definido por los vértices (1,0,0), (0,1,0) y (0,0,1):
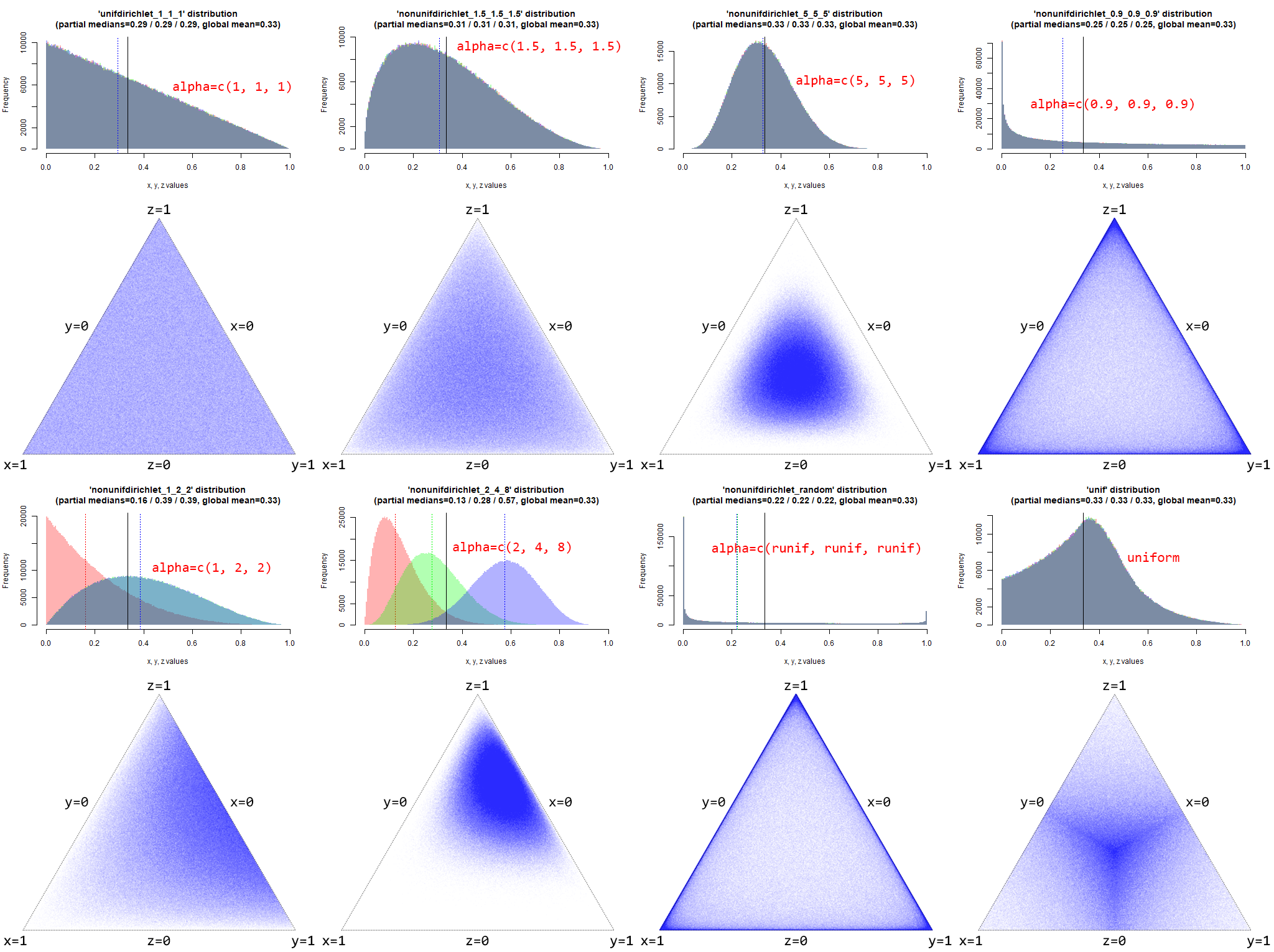
Empezamos por una distribución de Dirichlet uniforme, aquella en la que todos los valores del parámetro alpha valen 1. Para 1 millón de muestras dibujamos el histograma de las variables x,y,z (solapando con transparencia los tres histogramas), y además mapeamos su distribución 3D sobre un triángulo equilátero de lado unidad:

Como no podía ser de otro modo al cumplirse que x+y+z=1, el valor medio de las muestras de salida es 1/3=0,33. En el histograma podemos ver que la función de densidad de probabilidad desciende linealmente desde cierto valor para una salida nula (x=0, y=0 o z=0), hasta cero para salidas copadas por alguna de las variables (x=1, y=1 o z=1). El triángulo adquiere una densidad totalmente uniforme, lo que significa que todas sus localizaciones incluyendo bordes y vértices son equiprobables.
Ahora modificamos alpha hacia valores todos iguales mayores de 1, en concreto de 1,5. Esto constituye una distribución de Dirichlet simétrica que ya no se considera Dirichlet uniforme:

Con valores mayores de 1 en alpha, la salida nula (x=0, y=0 o z=0) empieza a tener una probabilidad nula de ocurrencia. También se reduce la probabilidad de una salida máxima (x=1, y=1 o z=1). En definitiva la distribución comienza a concentrarse en torno a valores intermedios. La media se mantiene en 1/3 pero las medianas parciales van acercándose a ella. El triángulo empieza a despoblarse en su periferia dado que ya no podemos alcanzar los vértices (x=1, y=1 o z=1), ni los lados (x=0, y=0 o z=0).
Este acercamiento de las medianas a la media lo constatamos con valores simétricos de alpha mayores, en este caso tomamos 5 para todos ellos:

No hay que ser muy avispado para ver que la distribución está mutando a una normal de media 1/3 y cada vez menos varianza. El triángulo se despobla completamente en la periferia haciendo ya imposible alcanzar valores extremos (tanto nulos como máximos).
Pero qué ocurre si manteniéndonos en una distribución Dirichlet simétrica ahora tomamos valores de alpha menores de 1?

El efecto es el contrario al visto con valores por encima de la unidad. Ahora la distribución se expande hacia los extremos haciendo más probable que las variables alcancen salidas muy altas (cercanas a 1), o muy bajas (cercanas a 0). En un ejercicio de distribución del % de voto, éste sería el comportamiento que mejor modelaría un caso real donde se hace factible que determinados participantes acaparen un alto % de voto al mismo tiempo que otros en importante número obtienen una representación exigua. Otro caso de uso que me toca de cerca y seguiría esta estadística es el consumo de TV: muy pocos usuarios realizan un alto consumo de cualquier canal de TV que escojamos, a la vez que un gran número realiza consumos bajos o muy bajos. En este caso nuestro triángulo divino gana densidad en los bordes a la vez que la pierde en el centro.
Ha llegado el momento de abandonar la distribución Dirichlet simétrica y ver qué pasa cuando usamos pesos en alpha difrentes, lo que constituiría una distribución Dirichlet asimétrica. Aumentamos a 2 los parámetros de las variables y,z manteniendo a 1 el peso de la variable x:

Las variables y,z alcanzan valores mayores mientras que x queda como la única variable que podrá llegar a valer 0 al mantener su ponderación en 1. Las medianas de y,z en consecuencia aumentan y se distancian de la mediana de x que se queda en valores muy bajos. El triángulo se despobla en las zonas cercanas a x=1, que ya no es alcanzable, y adquiere mayor densidad en la vecindad del lado x=0.
Por último asignamos un peso diferente a cada variable, con un valor de 2 para x, un valor intermedio de 4 para y, y el máximo de 8 para z:

Todas las periferias en general se despoblan ya que con parámetros por encima de 1 ninguna de las variables puede alcanzar valores extremos, pero en el triángulo la nube se aproxima con mayor densidad al lado x=0 y además se desplaza acercándose al vértice z=1, como era de esperar al ser respectivamente la variable x la que toma menores valores y la z la que los tiene máximos.
Para terminar con las distribuciones de Dirichlet vamos a aleatorizar al máximo el parámetro alpha asignándole en cada una del millón de muestras nuevos valores aleatorios uniformes en el rango [0,1] (recordemos que pesos inferiores a la unidad expanden la distribución final permitiendo valores muy bajos o muy altos):

El histograma deja claro que estamos ante un caso radical del ejemplo con alpha=c(0.9, 0.9, 0.9), donde ahora que una variable alcance el valor máximo de 1 es incluso más probable que se quede en valores intermedios. En consecuencia el triángulo está todavía más densamente poblado cerca de los bordes y más vacío en su interior. Este modelo puede servir como cota superior de un reparto altamente asimétrico en un proceso de votación por ejemplo.

En el histograma vemos que los valores de salida predominantes son intermedios como cuando usamos una Dirichlet con pesos mayores de 1, siendo aún bastante probable sacar un 0 mientras alcanzar máximos resulta muy poco probable. Curiosamente las medianas parciales coinciden exactamente con la media global, lo que imagino que será matemáticamente demostrable. El triángulo da lugar a un patrón tan bonito como (esto es intuición mía a la vista de un reparto tan antinatural) indicador de lo poco aconsejable que debe resultar esta distribución para modelar escenarios reales.
plot() o cualquier paquete gráfico porque "pintando" los datos sobre una matriz se tiene más control y, si se vectoriza, el volcado de los datos es instantáneo (hacer clic para ver en alta resolución):
img[cbind(M[,1], M[,2])] = img[cbind(M[,1], M[,2])] + M[,3]M[,3] en cada coordenada (M[,1], M[,2]) sobre la matriz/imagen img, tardando solo 30ms para "visualizar" los 100 millones de muestras previamente agrupadas.
No hay comentarios:
Publicar un comentario
Por claridad del blog, por favor trata de utilizar una sintaxis lo más correcta posible y no abusar del uso de emoticonos, mayúsculas y similares.