
El 'Teorema de la aproximación universal' afirma que siempre existe una red neuronal con una capa de salida con función de activación lineal, y al menos una capa oculta con funciones de activación no lineales, capaz de aproximar cualquier función continua con un error arbitrariamente bajo si se la provee de una suficiente cantidad de nodos ocultos.
Basándonos en lo anterior, podemos plantearnos lograr que una red neuronal aprenda a predecir las salidas de una función desconocida correspondientes a todas sus posibles entradas, en cuyo caso la "caja negra" sería intercambiable por la red neuronal.
En este ejercicio vamos a entrenar una red neuronal para tratar de que aprenda por completo un procesado complejo de imagen cuya implementación se desconoce:


La anterior transformación se ha hecho de forma determinista en Photoshop y se ha elegido especialmente intrusiva para ponérselo difícil a la red neuronal. Consiste en tres procesados:
- Curvas RGB
- Desaturación
- Rotación de tono
R' = f(R, G, B) G' = g(R, G, B) B' = h(R, G, B)
Este mapeo se puede implementar de forma determinista con reglas o en último término con tres LUT's 3D que abarquen todos los casos, lo que en 8 bits supondría codificar 3 · 256 · 256 · 256 = 50 millones de valores numéricos de salida. El interés de abordarlo con la red neuronal está en ver la precisión que podemos lograr con un modelo no lineal mucho más compacto.
Para entrenar nuestra red vamos a suministrarle un training set con la salida asociada a cada una de todas las combinaciones {R, G, B} de entrada en una codificación de 8 bits. Esto implica 256 · 256 · 256 = 16,8 millones de ejemplos.
~~~
Para entrenar nuestra red vamos a suministrarle un training set con la salida asociada a cada una de todas las combinaciones {R, G, B} de entrada en una codificación de 8 bits. Esto implica 256 · 256 · 256 = 16,8 millones de ejemplos.
Haciendo visibles a la red todas las posibles combinaciones discretas que luego ésta tendrá que predecir, buscamos que pueda aprender por completo la función a aproximar. Por ello y por tratarse de una transformación sintética sin ruido en los target, la posibilidad de overfitting no va a ser una preocupación así que no usaremos técnicas de regularización para prevenirlo. De hecho nos interesa sobreentrenar la red para que funcionalmente se asemeje lo más posible a un banco de memoria.
Vamos a mostrar el training set, correspondiendo la primera imagen a las features (valores {R, G, B} de entrada), y la segunda a sus correspondientes targets (valores {R', G', B'} de salida) resultantes de aplicar el procesado a modelar a la primera imagen.
Esta imagen sintética por cortesía de Bruce Lindbloom, contiene todos los colores que se pueden codificar en 8 bits (hacer clic en ella para verla en su tamaño original de 17Mpx):


Esta imagen sintética por cortesía de Bruce Lindbloom, contiene todos los colores que se pueden codificar en 8 bits (hacer clic en ella para verla en su tamaño original de 17Mpx):
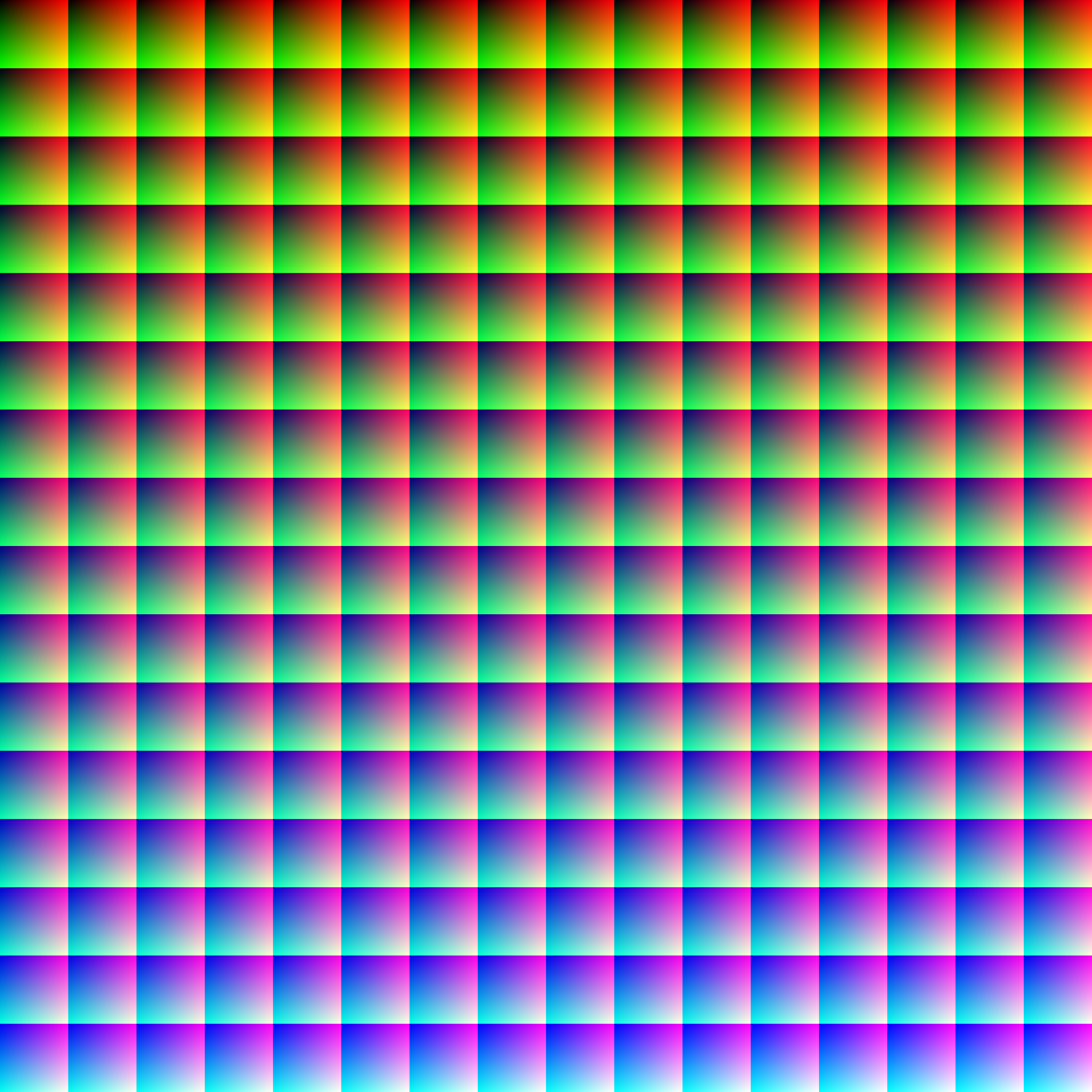
La anterior distribución espacial de colores es irrelevante porque la red no va a entender las imágenes como tales, sino como simples ternas de valores. De hecho lo primero que haremos será convertir todas las correspondencias de color entrada/salida en una tabla con tres features y tres targets por fila.
Sin embargo como las regresiones modeladas van a tener una aplicación gráfica final, en la validación de la red neuronal además de medir numéricamente el error medio podremos comparar visualmente la predicción para imágenes no "vistas" por la red con su procesado exacto.
Sin embargo como las regresiones modeladas van a tener una aplicación gráfica final, en la validación de la red neuronal además de medir numéricamente el error medio podremos comparar visualmente la predicción para imágenes no "vistas" por la red con su procesado exacto.
~~~
Los principales hiperparámetros que deberemos elegir serán el número de capas ocultas, el número de nodos por capa y las funciones de activación.

Tras hacer varias pruebas se sacan las siguientes conclusiones:

Finalmente escogemos una topología de red neuronal con dos capas ocultas y 64 nodos por capa (


La misma comparación para la segunda imagen de prueba:



Como puede verse las aproximaciones y el resultado exacto son indistinguibles; si las comparamos píxel a píxel solo percibiremos sutiles diferencias en las sombras profundas. Además nos podemos atrever a extrapolar que la precisión será similar con cualquier imagen que podamos imaginar, dado que en este caso la red ha sido entrenada de la forma más genérica posible.
Aquí se muestra una animación que da una idea de la mejora obtenida al aumentar el número de nodos, siempre sobre la versión de dos capas ocultas. La mitad izquierda de la imagen muestra el cálculo exacto determinista, y la derecha es la aproximación de la red neuronal:

Es interesante ver que lo primero que logra afinar la red conforme añadimos nodos son los colores, después los niveles de luminosidad, y por último el contraste, especialmente rebelde en las zonas de sombras.
Tras hacer varias pruebas se sacan las siguientes conclusiones:
- Con una capa oculta se hace difícil modelar correctamente el procesado, porque aún con un elevado número de nodos la red es incapaz de generar valores de salida cercanos a 0 (las sombras aparecen "lavadas"), lo que se manifiesta como una pérdida de contraste global.
- Usando dos capas ocultas sí es fácil hacer una buena aproximación sin elevar mucho el número de nodos. El modelo se hace prácticamente indistinguible del procesado exacto a partir de 32 nodos por capa.
- Como función de activación de las capas ocultas, y pese a que usar una ReLU parece estar de moda, obtenemos mejor resultado con la clásica sigmoide.
- Para la capa de salida usamos la función identidad por ser la adecuada en problemas de regresión. Dado que los niveles RGB esperables a la salida no deben ser nunca negativos, he comprobado que con una ReLU el resultado es idéntico.
Aquí la versión con 8 nodos por capa oculta de la red neuronal usada. El esquema es un objeto vectorial de MS Office dibujado sin apenas esfuerzo con NNPlot.
Finalmente escogemos una topología de red neuronal con dos capas ocultas y 64 nodos por capa (
MLP(64,64)). La sobreentrenamos (38 iteraciones, ~30min) porque como se ha explicado el overfitting es aquí excepcionalmente un aliado. No reservamos un validation set porque no es útil en este caso, y además no debemos diezmar nuestra muestra de entrenamiento ya que cada color aparece una y solo una vez en ella.
~~~
A continuación vemos el resultado de aplicar el procesado exacto a dos imágenes diferentes que constituirán nuestro test set, seguido de la aproximación obtenida con la red neuronal entrenada:La misma comparación para la segunda imagen de prueba:
Como puede verse las aproximaciones y el resultado exacto son indistinguibles; si las comparamos píxel a píxel solo percibiremos sutiles diferencias en las sombras profundas. Además nos podemos atrever a extrapolar que la precisión será similar con cualquier imagen que podamos imaginar, dado que en este caso la red ha sido entrenada de la forma más genérica posible.
Aquí se muestra una animación que da una idea de la mejora obtenida al aumentar el número de nodos, siempre sobre la versión de dos capas ocultas. La mitad izquierda de la imagen muestra el cálculo exacto determinista, y la derecha es la aproximación de la red neuronal:
Es interesante ver que lo primero que logra afinar la red conforme añadimos nodos son los colores, después los niveles de luminosidad, y por último el contraste, especialmente rebelde en las zonas de sombras.
Y en la siguiente imagen comparamos de forma visual el error obtenido con cada función de activación probada para las capas ocultas, siempre en la red de dos capas con 64 nodos por capa. Puede verse porqué la sigmoide fue escogida sobre la ReLU o la tangente hiperbólica.

Esto es una hipótesis mía, pero en un ejercicio donde tanto las variables de entrada como de salida solo pueden tomar valores mayores o iguales a 0, puede tener sentido pensar que funciones de activación que trunquen a 0 valores de salida negativos (sigmoide, ReLU) rindan mejor que las que permiten valores menores a 0 (tangente hiperbólica) .
~~~
Antes de acabar vamos a analizar tanto numérica como visualmente, la precisión de la aproximación de la red sobre la imagen de entrenamiento para contabilizar todas las posibles desviaciones que pueda cometer la red neuronal.
El siguiente histograma muestra para cada canal la distribución del error

Asi el error absoluto (
En la imagen mlp_64_64_error.png puede verse el error absoluto sobre todo el training set. Elegimos estos tres parches con predominio de sombras, tonos medios y luces:

Y a continuación mostramos en cada uno el error (enfatizado y en escala de grises) entre la aproximación y el valor exacto:



Lo primero que se hace notar es que los errores mayores coindicen con las zonas donde la salida sufre gradientes más pronunciados, ante una variación de la entrada que es siempre suave. Tiene lógica que a la red le cueste más aproximar cambios bruscos a la salida para una variación sutil de la entrada. Es de suponer que por ese motivo los parches de la predicción tienen también transiciones algo más suaves que los del procesado exacto.
Del mismo modo puede verse que los errores son algo mayores en las zonas de sombras (allí donde uno o más canales se acercan a 0). Esto encaja con los problemas que tuvimos usando versiones menos complejas de la red en las zonas con valores de color cercanos a 0, que la red no era capaz de generar, y cuadra con la mayor capacidad de interpolación que de extrapolación que en general tienen las redes neuronales.
Como ejemplo final una fotografía a gran tamaño para poder comparar con detalle (hacer clic sobre la imagen).

Si los datos de entrenamiento no pueden basarse en una imagen sintética que contenga todos los colores como la usada en el ejercicio, habremos de ser conscientes de que la red aprenderá a hacer el procesado sobre imágenes similares en cuanto a la distribución de colores a la usada para entrenarla. Sin embargo al aplicarla a imágenes que contengan colores que la red nunca ha "visto", el resultado puede ser impredecible.
Repositorio con el código Python y archivos auxiliares: GitHub.
El siguiente histograma muestra para cada canal la distribución del error
MLP(64,64) - Exacto. Los límites del error oscilan entre -4 y +7 niveles en la escala de 8 bits, pero la inmensa mayoría de aproximaciones resultan exactas o con un error de +/-1 nivel:Asi el error absoluto (
|MLP(64,64) - Exacto|) medio resulta prácticamente indetectable en una aplicación fotográfica, no llegando a medio nivel en ningún canal: 0,46 niveles para el canal R, 0,43 niveles para el G y 0,42 niveles para el B, relativos siempre a los 256 niveles disponibles en 8 bits.En la imagen mlp_64_64_error.png puede verse el error absoluto sobre todo el training set. Elegimos estos tres parches con predominio de sombras, tonos medios y luces:
{kind=link}
Y a continuación mostramos en cada uno el error (enfatizado y en escala de grises) entre la aproximación y el valor exacto:
Lo primero que se hace notar es que los errores mayores coindicen con las zonas donde la salida sufre gradientes más pronunciados, ante una variación de la entrada que es siempre suave. Tiene lógica que a la red le cueste más aproximar cambios bruscos a la salida para una variación sutil de la entrada. Es de suponer que por ese motivo los parches de la predicción tienen también transiciones algo más suaves que los del procesado exacto.
Del mismo modo puede verse que los errores son algo mayores en las zonas de sombras (allí donde uno o más canales se acercan a 0). Esto encaja con los problemas que tuvimos usando versiones menos complejas de la red en las zonas con valores de color cercanos a 0, que la red no era capaz de generar, y cuadra con la mayor capacidad de interpolación que de extrapolación que en general tienen las redes neuronales.
Como ejemplo final una fotografía a gran tamaño para poder comparar con detalle (hacer clic sobre la imagen).

~~~
Una red neuronal de este tipo en la práctica podría servir para hacer la ingeniería inversa de procesados de imagen complejos, como los filtros fotográficos que implementan muchas Apps, los filtros de cine que aplican los editores de vídeo, e incluso emular películas químicas antiguas (Kodachrome, Velvia,...) o sus procesos cruzados. Al tratarse de un aprendizaje supervisado se necesitaría siempre la imagen antes y después de aplicar el filtro.Si los datos de entrenamiento no pueden basarse en una imagen sintética que contenga todos los colores como la usada en el ejercicio, habremos de ser conscientes de que la red aprenderá a hacer el procesado sobre imágenes similares en cuanto a la distribución de colores a la usada para entrenarla. Sin embargo al aplicarla a imágenes que contengan colores que la red nunca ha "visto", el resultado puede ser impredecible.
{kind=link}
~~~
Repositorio con el código Python y archivos auxiliares: GitHub.
No hay comentarios:
Publicar un comentario
Por claridad del blog, por favor trata de utilizar una sintaxis lo más correcta posible y no abusar del uso de emoticonos, mayúsculas y similares.