
Seguramente k-means sea el algoritmo de clustering más conocido a nivel académico, pero poco usado en aplicaciones del mundo real por su carácter impredecible y poca robustez en general frente a distribuciones complejas. Aquí vamos a estudiar un caso de uso en el que k-means sí resulta efectivo por los motivos que comentaremos.
Se trata de "restaurar" imágenes pixel art que podamos encontrar en la Red para devolverles su estado nativo original:
- Cada píxel de la imagen final corresponderá a un solo píxel nativo del pixel art primitivo (es decir serán imágenes reducidas a tamaño icono con muy pocos píxeles por lado).
- La paleta de colores original también se tratará de recuperar, reduciéndola a un conjunto mínimo de colores básicos (típicamente del orden de 10 como máximo).
~~~
Para el primer ejemplo partimos de la siguiente imagen pixel art deteriorada, en este caso por los artefactos derivados de la compresión JPEG. Nunca se debería guardar en este formato nada que no sea una fotografía pero se hace constantemente.

Por la compresión del formato el color en las celdas no es uniforme, y aunque perceptualmente podemos distinguir los colores compartidos, numéricamente son todos diferentes debido al ruido:

El tamaño nativo del pixel art lo obtenemos simplemente contando "píxeles": en este caso 38x43 (ancho x alto). A continuación recorremos la imagen promediando el color en cada uno de estos "píxeles". Hacerlo por mediana es más conveniente que usar la media para ser más robustos frente a outliers (contaminación cerca de los bordes de las celdas o píxeles con ruido espúreo).
Además solo usamos la parte central de cada celda, aplicando una guarda configurable para descartar los bordes. En el ejemplo este margen resulta recomendable para evitar que la cuadrícula negra original participe en el promediado de mediana. En la siguiente imagen se marca en gris la guarda descartada:

Calculada la mediana en cada una de las celdas reducimos la paleta de color pero lejos todavía de la paleta mínima a la que aspiramos. A k-means le debemos suministrar el número de clústers (colores o combinaciones RGB) en que debe segmentar la imagen. Podríamos tratar de contar colores sobre la imagen original pero resulta más sencillo analizar la imagen en el espacio RGB y limitarnos a "contar clústers":

Como puede verse los clústers se hacen muy evidentes porque el ruido que contienen supone una dispersión muy controlada. Corresponderían a una paleta base de exactamente 15 colores distintos. Aplicando una segmentación con k=15 segmentos tenemos el pixel art final restaurado en una imagen de 38x43 píxeles totales y una paleta de 15 colores únicos:

El reparto de píxeles por clúster lo podemos ver en el siguiente histograma:

Si en lugar de por inspección visual hubiésemos querido obtener el número óptimo de clústers con el clásico elbow method, por la bajísima dispersión de colores en sus respectivos clústers debería producirse un cambio brusco justo en el valor óptimo para k:

Si esto no se da es solo porque la escala lineal impide ver dicho cambio. Tomando logaritmo aparece el codo exactamente en k=15:

~~~
Repetimos el proceso con una fotografía del dibujo de un Pokémon en papel:

Tras corregir la perspectiva en Photoshop para traer la imagen al universo cartesiano, tenemos el resultado de calcular la mediana del color en cada celda. Las diferencias de tonalidad son visibles a simple vista fruto de las irregularidades de la fotografía original:

Esta corrección la podríamos hacer sin salir de R con el algoritmo implementado en 'Transformación trapezoidal de imágenes con R (I). Algoritmo', pero aquel estudio llegó después.
Basta mirar la imagen para intuir los 4 colores básicos que la componen, corroborados por el scatter de color. En este caso los clústers son mucho menos compactos que con Boba Fett pero por estar situados en puntos tan alejados entre sí en el espacio RGB, siguen siendo inequívocamente identificables. Se superponen con cierta transparencia los centroides generados en la segmentación con k=4:

Como era predecible tenemos un codo en k=4:

Y aquí la reconstrucción del pixel art original:

Este Pokémon segmentado lo usaremos como ejemplo demostrativo en 'Mapas estilo LEGO con R' para generar esta creatividad (hacer clic para ver en alta resolución):

~~~
Vamos con ejemplos que se lo ponen un poco más difícil a k-means. Este Octocat, la mascota de GitHub, proviene de un GIF animado que encontré aquí:

Si sientes curiosidad el Octocat no es exactamente un gato sino gato y pulpo a la vez, y es hembra.

Cuando promediamos por mediana y dibujamos el scatter nos encontramos con 9 clústers definitorios. Aunque sutiles, se puede notar que hay dos tonos de gris próximos y lo mismo ocurre con otros dos tonos crema. Estas diferencias casi se notan más a simple vista que en el gráfico (hacer clic sobre la imagen para verla en más detalle):
Cuando promediamos por mediana y dibujamos el scatter nos encontramos con 9 clústers definitorios. Aunque sutiles, se puede notar que hay dos tonos de gris próximos y lo mismo ocurre con otros dos tonos crema. Estas diferencias casi se notan más a simple vista que en el gráfico (hacer clic sobre la imagen para verla en más detalle):
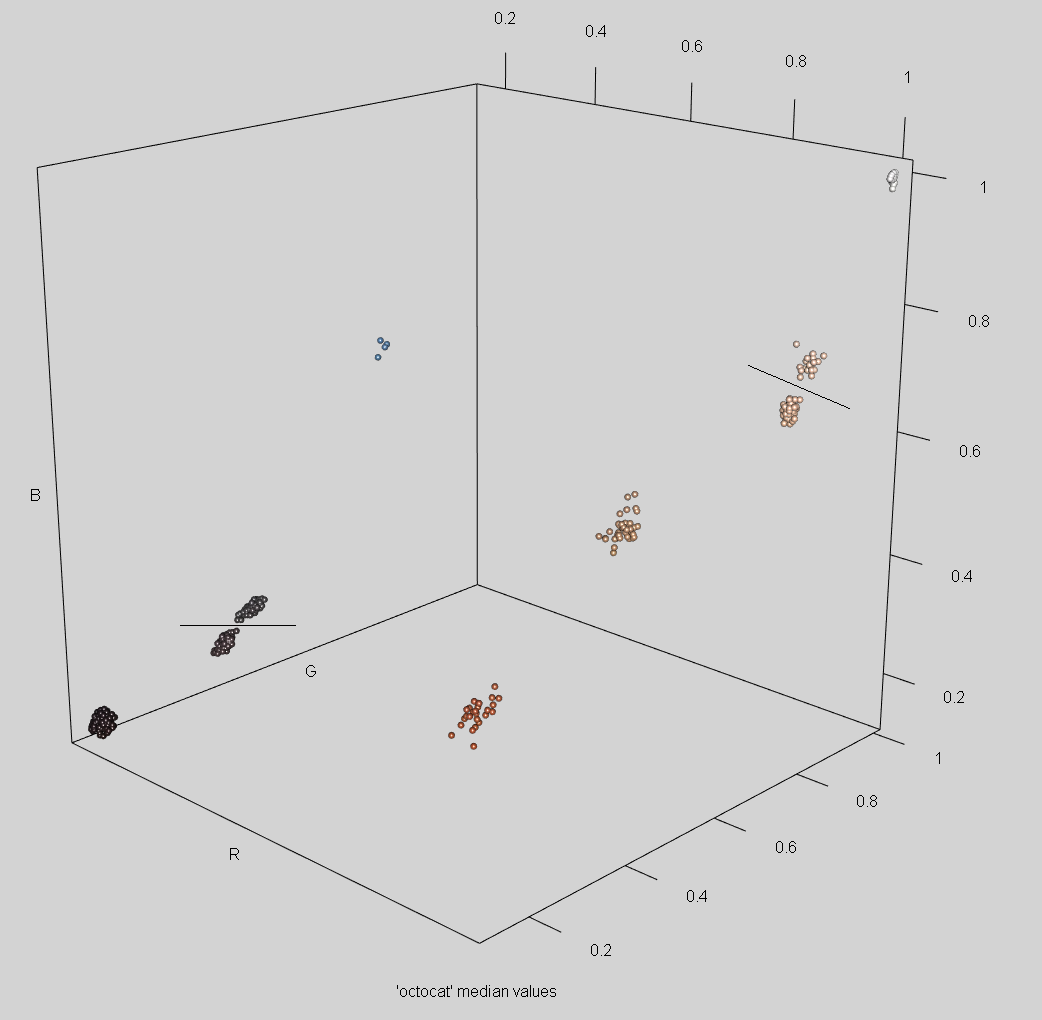
En este caso confiar ciegamente en el elbow method seguramente nos habría hecho perder uno de los matices de color:

La imagen restaurada queda así con los 9 colores únicos:

~~~
Y pasamos de un gatopulpo a un erizo, Sonic!

Calculando el scatter queda claro que la imagen se define con 14 colores, incluyendo tres tonalidades de azul, cuatro gamas de gris (con el blanco y el negro) y dos de rojo:

Aquí, como nos ocurrió con Boba Fett, la poca dispersión se traduce en un quiebro inconfundible en k=14:

En ejecuciones iniciales de k-means con k=14, el clúster de tonos amarillos no se genera. Sin embargo parametrizando un valor muy alto de
Esto da idea de lo poco previsible y sensible que es el algoritmo: aquí sabíamos que el clúster existía e "íbamos a por él", pero qué pasa cuando tienes un conjunto de datos enorme y no sabes cómo ayudar a k-means?






El resultado ya no tiene diferenciación de color donde no debe, y es perfecto a falta de un muy pequeño número de píxeles puntuales que no fueron clasificados en su color correcto (en general píxeles que deberían haber sido grises pero acabaron marcados como marrón oscuro):


Y aquí un resumen final de todos los ejemplos comparando con la fuente:

Hablemos de por qué k-means ha tenido éxito en este tipo de aplicación y dónde podría fallar.
k-means ha funcionado bien básicamente porque lo tenía fácil. A la vista de los scatters 3D nos damos cuenta de que tras el promedio de mediana, la dispersión alrededor de los centroides en los pixel art es siempre muy baja, como era esperable, definiendo perfectamente los clústers y no existiendo outliers.
nstart (90.000) el clúster aparece sin necesidad de aumentar k. Hemos tenido que subir mucho las iteraciones aleatorias iniciales para que el mini-clúster se llegue a "descubrir".Esto da idea de lo poco previsible y sensible que es el algoritmo: aquí sabíamos que el clúster existía e "íbamos a por él", pero qué pasa cuando tienes un conjunto de datos enorme y no sabes cómo ayudar a k-means?
~~~
Para terminar un caso que, requiriendo algo de proceso manual (en concreto corregir la perspectiva y eliminar el fondo de la fotografía original, que hemos sustituido por color verde en el archivo TIFF), presenta una dificultad considerable:
El scatter de la imagen deja claro que la tarea no estará exenta de algún fallo, pero veremos qué tal lo hace k-means. Al provenir de una fotografía, como ya nos pasó en el Pokémon los clústers tienen mucha más dispersión, pero aquí el problema es mayor por ser superior la gama de colores (hacer clic sobre la imagen para verla en alta resolución):
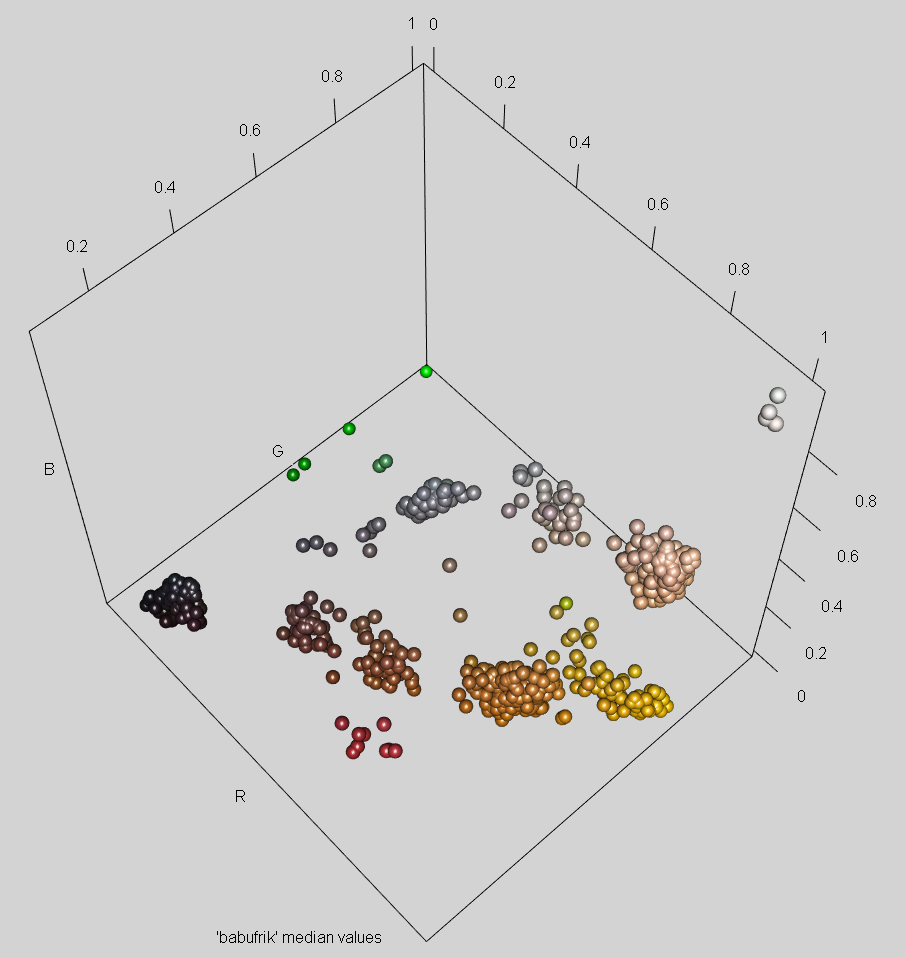
A la vista de las agrupaciones presumimos unos 10-11 colores reales únicos, que más el verde sintético supondrían 11-12 clústers como mínimo. Sin embargo para diferenciar el color rojizo de las orejeras necesitamos un clúster adicional y subir de forma considerable
nstart, así que segmentamos con k=13 resultando estos centroides:
Despojado el fondo del color verde, el resultado aunque no es perfecto (sobre todo en las gamas de marrones), es muy bueno si tenemos en cuenta que partimos de la fotografía de un pixel art físico. La mediana además ha absorbido muy bien el efecto del punto central oscuro que encontramos en cada cuadrícula, valores que pueden considerarse outliers:
Podemos refinar fusionando manualmente los dos clústers ocre, que por ser tan parecidos (vimos lo próximos que estaban sus centroides) introducen diferencias ficticias indeseables:
> centers[7,]=(centers[7,]+centers[10,])/2 > centers[10,]=centers[7,]El resultado ya no tiene diferenciación de color donde no debe, y es perfecto a falta de un muy pequeño número de píxeles puntuales que no fueron clasificados en su color correcto (en general píxeles que deberían haber sido grises pero acabaron marcados como marrón oscuro):
Si se crearon dos clústers verdes segmentando con k=13, y hemos fusionado dos de los clústers de color, eso significa que la porción de personaje en la imagen final se forma finalmente con 13 - 2 - 1 = 10 colores únicos.
Para Babu Frik el elbow method no habría ayudado. La alta dispersión original hace complicado poder establecer el número de colores atendiendo a la gráfica ya que incluso en escala logarítmica se muestra muy progresiva:
~~~
Y aquí un resumen final de todos los ejemplos comparando con la fuente:
~~~
Hablemos de por qué k-means ha tenido éxito en este tipo de aplicación y dónde podría fallar.
k-means ha funcionado bien básicamente porque lo tenía fácil. A la vista de los scatters 3D nos damos cuenta de que tras el promedio de mediana, la dispersión alrededor de los centroides en los pixel art es siempre muy baja, como era esperable, definiendo perfectamente los clústers y no existiendo outliers.
Por otro lado aunque en k-means puntos muy alejados del centroide penalizan mucho, lo que incentiva la creación de clústers exclusivos para píxeles de colores muy aislados, si un elemento es muy minoritario no sería difícil que k-means lo obviase como nos pasó al principio con los píxeles amarillos de las deportivas de Sonic.
El siguiente ejemplo tiene visualmente dos clústers, gris y amarillo, o eso podríamos encontrar en un pixel art afectado por ruido. Se trata de una imagen de 30x30 píxeles con un único píxel amarillo y los demás repartidos a partes iguales en tonos grises muy cercanos:

Tras una segmentación con k=2 los dos clústers creados se corresponden con dos tonos de gris, quedando asignado el píxel amarillo al clúster menos oscuro (la influencia del píxel amarillo en el cálculo del centroide la vemos en la ligera desviación de éste respecto a los valores R=G=B=35):
> kmeansfit$centers*255 R G B 1 20.00000 20.00000 20.00000 2 35.47672 35.47672 34.92239El error medido como distancia euclídea entre el píxel amarillo y su centroide, pese a ser muy grande, pesa menos en el cómputo que la suma de todos los errores que se tendrían debidos a demás píxeles si hubiese un solo clúster de tono gris para ellos. Para que el píxel amarillo tenga su propio clúster no hay más remedio que aumentar a k=3 el número de segmentos.
~~~
Repositorio con el código R y archivos auxiliares: GitHub.
No hay comentarios:
Publicar un comentario
Por claridad del blog, por favor trata de utilizar una sintaxis lo más correcta posible y no abusar del uso de emoticonos, mayúsculas y similares.